Brian Lester

Senior Research Engineer
May 2022–Present
AI Resident
October 2020–May 2022
Interesting in efficiently leveraging massive pre-trained transformers and adding structured prediction atop powerful local features created by large contextual embeddings.
Prompt Tuning—an efficient method of controlling large pre-trained language models. Matches performance of full model fine-tuning with T5 using only 0.003% of the parameters. Open-sourcing of our Prompt Tuning code base has enabled 3 published paper, 1 product launch, and at least 5 in-flight papers.
Flan—Multitask training for a 137 billion parameter transformer-based decoder-only language model to create a model thiat is better at zero-shot prompting, few-shot in-context learning, and Prompt Tuning. This shows Prompt Tuning can be applied to large models, in both absolute parameter count (137 billion) and depth (64 layers).
SPoT—Using multitask prompts as strong initialization for Prompt Tuning resulting in increased performance. With a SuperGLUE test set performance of 89.2 we are just 0.1 point behind fine-tuned T5 using only 400K parameters per task instead of the 11B parameters per task like T5 XXL uses. We also used the similarity between prompts on different tasks to estimate task similarity. Using this prompt similarity metric we were able to select just 3 pre-training tasks that recovered half of the performance gain realized from a brute force search (which would requiring 48 different runs).
Added partial network training, lazy loading, and auto-regressive cache pre-filling of T5X, the open-source reimplementation of T5 in Jax. This final change reduced inference latency from 30 seconds to 2.4.

Machine Learning Engineer—Specialized in using Deep Learning for Natural Language Processing (NLP). Researched new and effective training methods and model architectures, built client-facing models for production, and created infrastructure that enables distributed, cloud-native, training and horizontally scalable model serving.
I maintain Mead-Baseline—our open-source deep-learning toolkit. It is the go to path for all deep learning work (research and production) within the company. I have created performant, batched implementations of various complex neural network architectures including a Conditional Random Field (CRF) and Beam Search.
Designed the label space and annotation guidelines for the Natural Language Understanding module of a customer facing dialogue system in the self-service technical support domain for a cyber security company. My design focused on general intents, slot values (which were combined to form complex entities), and relations to cover diverse and complex conversational domain.
Created our cloud-native, deep-learning model training platform. Our platform is a Directed Acyclic Graph (DAG) execution engine powered by kubernetes that can run a pipeline of tasks where each step can be anything that can be run inside of a docker container. Our platform automatically parallelizes non-dependent nodes in the DAG (allowing for efficient Hyper Parameter Optimization (HPO)) and can distribute the computation of a single step in the pipeline over multiple GPUs and compute nodes. Using Kubernetes allows for effective sharing of cluster resources among disjoint users. The platform enables building mutli-step pipelines that can transform raw training data into a model that is ready for production.
Created and maintain our deep-learning model serving infrastructure. The server, backed by TensorFlow Serving, enables rich Natural Language Understanding (NLU) via cascading calls to a series of deep learning models. Both the server itself and the TensorFlow Serving backend are deployed via Kubernetes. The server includes components that are reusable across clients and also supports an extensive plugin system for client specific operations. This server is currently powering NLU for several production dialogue systems.
Created a wide range of Machine Learning models powering client-facing production models. The architectures and tasks range from ConvNets for classification (used in intent detection, text categorization, and sentence segmentation), mention-ranking models for relation extraction, bLSTM-CRF taggers for general purpose tagging (NER, POS, Chunking) as well as client-specific slot filling, to Transformer-based seq2seq models used to automatically suggest agent responses. Production models were also calibrated to produce reliable scores via a mix of post-hoc methods and auxiliary confidence models.

Lead Machine Learning Research Engineer—Used machine learning, natural language processing, computer vision, and cutting edge deep neural networks to power improve heuristic based existing features and create new features. Designed and Implemented our model serving infrastructure that processed 200 million emails an hour. Provided technical leadership to the data science team.
Trove would detect and surface sentences in emails that warranted a response to help track emails that were important to reply too. This was originally done via a tangled mess of regular expressions. Using unsupervised methods and iterative refinement I bootstrapped a dataset of these sentences. Using a ConvNet I was able to create a system better than the regex. The ConvNet was also able to account for semantic meaning and we refined the product so that it highlights requests that can be handled via email not just any ask. The results of this model became a staple feature in the annotated email social graph that trove created.
Used a neural ranking model to preform coreference resolution by linking anaphors to their antecedents. By replacing pronominal mentions in the question snippets extracted from emails we were able to provide context to the users.
Used lexical features from the email as well as connectivity information in the email social graph to identify bot accounts. We used a broad definition of bots to include things like newsletters and automated email from things like github. We used these classification labels to help filter search results.

Software Engineering Intern—Specialized in Voice Recognition and User Information Systems.
Prototyped and Vetted Dragon Drive Link, an on-board real-time driver information and entertainment application similar to Android Auto.
Research, designed, and implemented a system to optimize Voice Recognition used in Production Mazda cars. It dynamically decides if it should display a menu of disambiguation options based on the users past interactions with the system. We patented the system (US 9984688B2)
June 2025
An overview of my work on the Common Pile (paper, data, code), an 8TB dataset of openly licensed text, and the first the produces models that are on par with compute and data matched proprietary models.
SlidesJanuary 2022, November 2021
A comprehensive overview of my work on Prompt Tuning (The Power of Scale for Parameter-Efficient Prompt Tuning, Finetuned Language Models Are Zero-Shot Learners, SPoT: Better Frozen Model Adaptation through Soft Prompt Transfer) as well as insights gained from other papers. Features a thick stack of references that can serve as a deep dive into the soft prompting space.
SlidesDecember 2018
A spotlight talk, at the Open Source Software workshop at NeurIPS 2018, highlighting the advantages of using our open-source, model-building toolkit, Mead-Baseline, which provides high-level model abstractions, correct evaluation metrics, and fast runtimes. Mead-Baseline is the foundation of all Deep Learning work, in both research and production, at Interactions.
SlidesMarch 2020*
In most settings, one trains a model and then evaluates it on some held out test set; however, there are some domains where one would rather have no answer than an uncertain one. For example, if you have a human in the loop you might want to send an example to the human to double check it rather than just using the label produced by the model. Confidence models allows one to make decisions about how much trust to put into a model's predictions.
This talk outlines the idea of confidence modeling, techniques used to evaluate models that allow for the rejection of examples based on confidences, the difficulties of getting well calibrated posteriors from Deep Learning models, and a summary of current work—using calibration techniques and auxiliary models—to produce high-fidelity confidence scores in the Natural Language Understanding module of a real world Dialogue System.
*Cancelled due to COVID-19February 2020
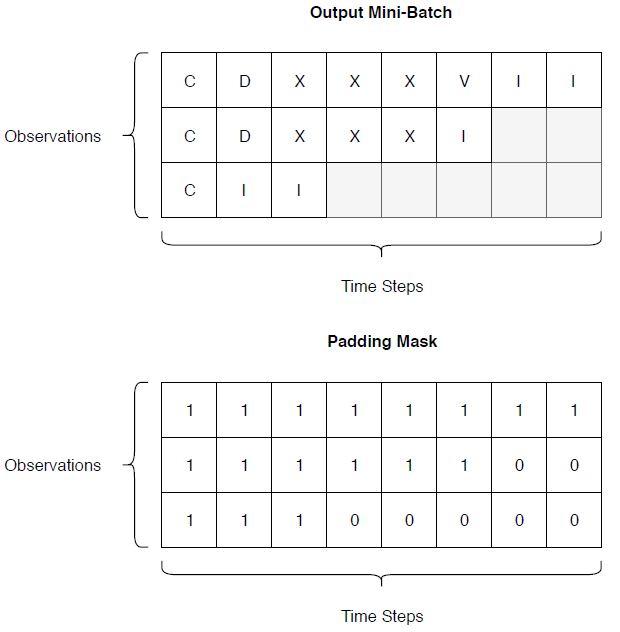
To efficiently train Deep Learning models processing multiple examples at once—aka batching—is paramount. The rub is that in NLP data often have differing sizes. We rectify this by adding empty data to smaller examples to bring them up to size: a technique we call padding. Padding comes with its own set of problems; if you aren't careful, calculations will include your padding elements and produce incorrect results.
In this practitioner focused talk we cover how to batch, pad, and mask a range of neural network layers common in NLP including operations that obviously require masking like mean pooling, token level losses, and attention; complex operations like the CRF forward algorithm and Viterbi decoding; and subtle operations that you might not expect to require masking such as max pooling following a 1D convolution.
SlidesJanuary 2020
Based on a recent thread in the Ann Arbor data science Slack, this talk walks through the collaborative optimization of some numeric code. Beginning with a correct but slow implementation in Python, we will work though a series of improvements using NumPy, the Swiss army knife of scientific computing in Python. This talk will introduce core NumPy concepts like broadcasting and vectorization, and will wrap-up with a bespoke implementation in Cython for a blisteringly fast solution that can scale up to 10s of thousands of points in just second compared to the multi-hour runtime of a pure python soltuion.
SlidesExtensive experience in using Jax, Flax, TensorFlow, PyTorch, and Scikit-learn for Machine Learning (ML), specifically Natural Language Processing (NLP), research and applications.
Deep Understanding of building and deploying applications with Kubernetes, Docker, Flux, Prometheus, Apache Nifi, MongoDB, GitLab CI/CD, and GitHub actions.
Experience with Data Science toolkits such as NumPy, Pandas, Faiss, Gensim, SpaCy, NLTK, SciPy, Tensorflow-Datasets, Seaborn, and Matplotlib.
In-depth understanding of Python, Cython, Java, and C. Experience with \(\rm \LaTeX \), C++, HTML, CSS, Javascript, and enough ELisp to create a pretty tricked out Emacs config.
April 2021
Code to reproduce my EMNLP 2021 paper, The Power of Scale for Parameter-Efficient Prompt Tuning. Built on T5X, a reimplementation of T5 in JAX, this code base allows for the training of prompts on Google Cloud TPUs. It also includes extended setting such as factored prompts and partial attention masking. It has been the foundation of our follow up reserach and should serve as a great starting point for your work.
Fall 2021
A simple 2-bit Quantum Computer simulator in Python based on the Gate Quantum Computation model. It includes methods for combining qubits into a single representation, and for factoring that transformed vector back into a sequence of qubits. Representing \(n\) qubits as a single vector results in a vector of size \(2^{n}\), which is suggestive of the expoential memory requirements of simulating a quantum computer on a classical one. The math of the simulation also sheads light some of the weirder aspects of Quantum Mechanics. For example, entangled qubits results in an unfactorable vector. This in turn means that the qubits must be measured together, resulting in only the states where the qubits are equal (as is observed of entangled qubits in real life) being possible.
2018–2020
Core contributor to Mead-Baseline, a deep-learning toolkit for NLP that provids a uniform API to both TensorFlow and PyTorch backends, reusable implementations of complex neural architectures and layers, strong deep learning based models and good hyper-parameters, robust and correct evluation metrics, and performant batched implementations. Mead-Baseline uses Inversion of Control and an extensive plugin system to enable quick experiments by changing sections of model archetecutre with just a few lines of code. Model archetecture and training regime are specified in a configuration file to allow for repeatable research. Mead-Basline also enables easy access to a variety of contextual embeddings in the form of large pretrained language models like ELMo or BERT. Mead-Baseline also includes exporting utilities to convert models into either tensorflow serving servables or ONNX traced models which are ready to be deployed. Mead-Baseline is a one-stop shop that can take models all the way from prototyping to production.
My main work has been on the API design and implementation of the lower layers. I batched both the Conditional Random Field and the Beam Search yielding 6x speed ups. Before development on the framework basically stopped I created DyNet implementations of all the models in Mead-Baseline including large transformers. I introduced the ability to perform Constrained Decoding on the CRF where the rules of the transition scheme can be used to narrow down the number of possible transitions when doing Viterbi Decoding. Constrained Decoding gives gains across the board and should always be used.
November 2020
A small library for parsing, converting, and manipulating span level NLP tasks (NER, slot-filling, etc) that are encoded as token level annotations like IOBES or BIO. A paper describing this library, and the need for standardized tools for span level NLP, was published at the second workshop on NLP Open Source Software.
An implementation of Text Rank in Python that reproduces the results from the original paper. I currently use it as a vehicle for personal research: investigating if deep learning based sentence similarities will yield better summaries. Results forthcoming.
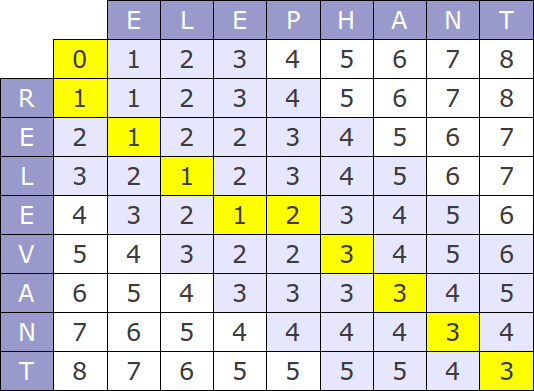
A collection of various minimum edit distance algorithms as well as token based methods like Jaccard overlap. The algorithms are implemented in Cython and scale well. The library is able to compute minimum edit distances between entire Wikipedia pages in under asecond.
Implementations of Locality Sensitive Hashing. Supports using MinHash to approximate Jaccard similarity and Random Hyperplanes for a cosine based LSH. Also provides utilties to estimate optimal band size for some desired threshold of similarity. This library enables users to find similar items in very large corpora quickly.
April, 2020
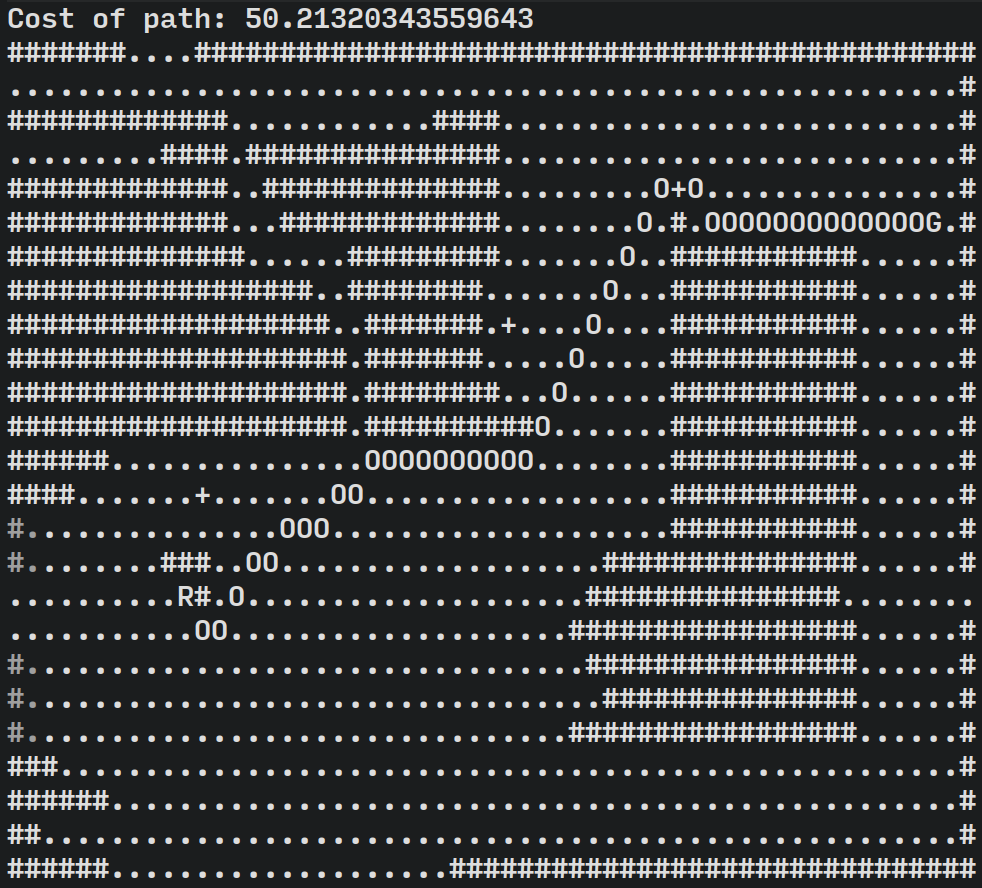
Various path-finding algorithms via dynamic programming. Algorithms implemented include:
Algoritms are agnostic to the implementation of the underlaying graph implementation. Both grid-based and adjaceny-based graphs are provided.
Path-finding with fuel-based constraints—effectivly a
maximum path distance—and refill stations is also
included. This is done in a two step procedure using a
meta-graph. First minimum distance paths are found between all
combinations of the staring position, the ending positions, and
all refilling stations. Then, any path longer than the fuel
capacity is removed. The result is a meta-graph of reachable
points with edges weighted based on the length of the path. Then
the same shortest-path algorithm is applied to this meta-graph
to find a path between the start and end positions that travels
through required refilling stations. The final path is then
reconstructed by replacing the abstract path of
Node a→Node b in the
meta-graph with the actual path from a to be found in step one.
I have a collection of libraries hosted on PyPI, most enable narrow data science verticals but some are generic utilities.
A decorator that lets you mark a function parameter as a file. This will automatically open the file when the function is called. This lets you write easy to test function that assume pre-opened files but allows your users to pass in file paths as strings.
It also includes the ability to automatically do shadow
paging by pre-pending a write mode file with a
s. This is done by proxying all the writes to a
temporary file and then when you close the context manager
the file was opened in the original file is replaced with
the temporary file. This allows for atomic writes.
Utilities to read and write common word vector formats such as word2vec and glove. Also introduces a new format called Leader which is a binary format like word2vec but we prefix the word with its length. This allows for reading without having to iterate over characters like word2vec does at the cost of just 3 bytes of disk space per word. Our benchmarks show this format is faster for all common pre-trained embeddings. A paper describing the new embedding format, benchmarks done, and the library can be found here.
A small, extensible, in-memory inverted index to quickly
added full text search to a script. It also includes a
prompt_toolkit completer that will search the
inverted index as you type. Selecting an option will replace
the input with that value. This is useful for when there are
a lot of options to choose from and you want to provide a
fuzzy search when looking for the right one.
Lightweight utilities to download and load both the MNIST and Fashion MNIST datasets. The only dependency is NumPy.
A GUI around surfraw that lets you open a search box from anywhere, it also lets you do a search where the query is whatever text is highlighted.
A dictionary subclass that stores the sha1 hash of keys rather than the full key. This reduces storage space, for example if your keys are long documents you can store and retrieve stats about them without storing the whole document in memory.
An interface that gives the probability that a token should be capitalized. Probabilities were estimated from the CNN/DailyMail dataset.
An LSH implementation that supports Jaccard Similarity through MinHash and cosine similarity via Random Hyperplanes.
Cython implementations of various string distance algorithms.
Pedagogical implementations of various time-stamp encoding algorithms.
Dependency parsing via Deep Learning models written in PyTorch. Supports training parsers via dynamic oracles using either the Arc Eager or the Arc Hybrid transition scheme or a Graph based parser using Biaffine Attention. Currently working on creating a shared interface between the two parser types with plans to release it as an open source library
Winter 2017
A reimplementation of the paper “A Decomposable Attention Model for Natural Language Inference” in DyNet. I was able to reproduce the paper results via extensive hyper parameter tuning
Fall 2016
Using a deep convolutional network steering angles are predicted from a front facing camera. The network is 20 layers deep and uses various network architecture modifications to decrease training times. These include residual connections and batch normalization.
Summer 2016
Using a deep convolutional network, written in Tensorflow, multi-digit sequences (up to five digits) are classified. This is done using an end-to-end network that recognize the digits in one step rather than creating separate parts that localize the digits, segment them, and then classify each digit individually. This network was trained using the Stanford Street View House Numbers Dataset and achieves 93.89 percent accuracy on the test dataset. Read the full write up here
Fall 2015
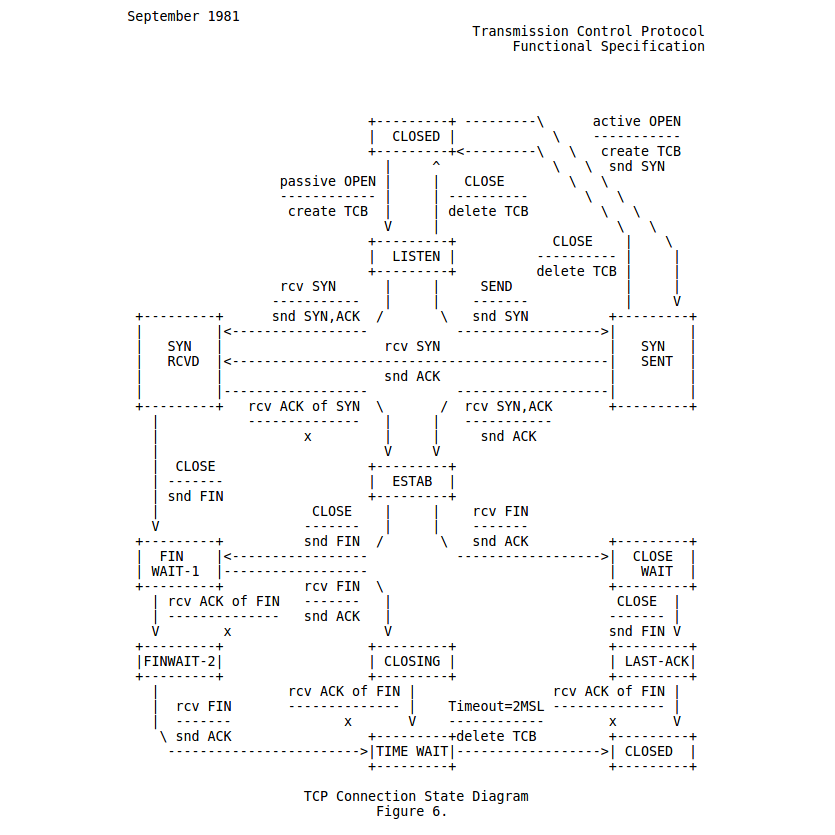
Implementation of the Transmission Control Protocol (RFC 793) completed for Data Communications and Computer Networking. This implementation is fully functional TCP implementation required to ensure both packet delivery as well as in-order delivery of packets. This implementation also supports multiple in flight packets with using the "Go Back N" strategy. This requires the Minet framework to function.
Spring 2015
Particle interaction simulation written in C++. This simulation was written for parallel computation using the Message Passing Interface (MPI) and run on the Stampede super computer at Texas Advanced Computing Center. The simulation was carried out using the Ring Algorithm. Analysis of the program showed linear speed up as the number of processors was increased.
Spring: 2016
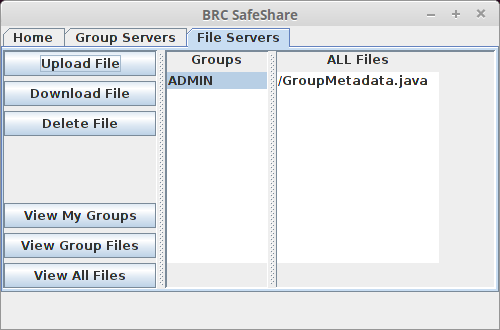
Distributed group-based file sharing system written in Java. This includes a multi-threaded group server that handles user authentication and distributes token to users. Multi-threaded file servers use the tokens to distribute files only to approved users. A GUI for clients to access files was also created. This Systems is secure as well. Cryptographic tools like symmetric and public key cryptography, Diffie Hellman key exchange and digital signatures are leverage to create secure authentication protocols that provide perfect forward security, repel man in the middle attacks, and provide plausible deniability. This system uses two-factor authentication via a Time based One Time Password (TOTP) scheme as outlined in RFC 6238.
Winter 2021
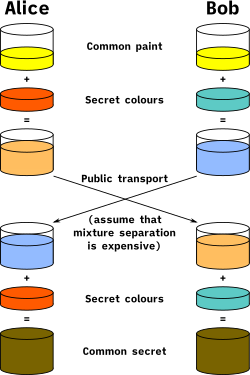
A small example of how two parties can use some public information and a secret that each of them keep to derive a shared secret over public, un-trusted communication channels using Diffie-Hellman Key Exchange. Working from a shared prime number \(n\) and a primitve root modulo \(n\), \(g\), Alice and Bob can derive a shared key based on private information they each have, \(a\) and \(b\) (integers between \(1\) and \(n\)) respectively. Alice sends Bob \(g^a \;\mathrm{mod}\; n\) and Bob sends Alice \(g^b \;\mathrm{mod}\; n\). Bob then raises Alices results to the power of \(b\) while Alice raises Bob's to the power of \(a\). This results in both of them having a shared secret— \(g^{ab} \;\mathrm{mod}\; n\). An attacker, Eve, seeing only the public information can only calculate \(g^{a+b} \;\mathrm{mod}\; n\) without solving the descrete log problem.
Summer 2016
Facial detection and recognition in video streams. Facial detection is done with dlib's CUDA accelerated histogram of ordered gradients frontal face detector to find faces and then dlib again to estimate facial landmarks. These landmarks are then transformed using an affine transformation in openCV to center the face in the image. Embeddings are then generated using a deep neural network written in torch from the OpenFace project at Carnegie Mellon University. These embeddings are can then be classified by various machine learning techniques. This project used a support vector machine from Scikit-learn to classify the faces in the image.
Spring 2016
A compiler written in C to compile an Object-Oriented language called MINI-Java. Lexical analysis is done using code generated by Lex based on specified regular expressions. Syntax analysis is done using a Context Free Grammar and Yacc. This syntactic analysis produces an Abstract Syntax Tree that is then parsed in the Semantic analysis phase.
Spring 2016
A simple program for breaking Vigenere Ciphers for homework 2 of CS 1653 at the University of Pittsburgh. This program works by tracking the distances between sets of repeating characters to try to estimate the length of the key. I didn't have time to implement frequency analysis to try to figure out what the key actually was. This program is written in C and includes a C implementaion of a Red-Black tree (used to track the offsets between repeating sequences of characters).
Spring 2015
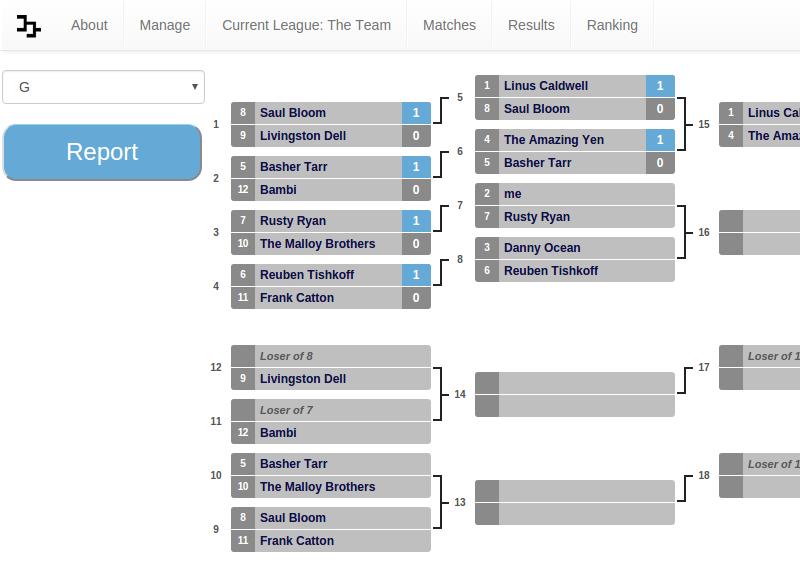
A web app that allows users to create a league, schedule matches, report and track results, and rank participants using the Elo ranking system. Once league rankings have been established integration with challonge allow users to run tournaments that are automatically seeded based on the Elo ranking of the players. This was created for CS 1520 in collaboration with Chris Price, David Robertson, and Troy Taylor. The app is written and deployed with Google App Engine. A live demo is found here.

Ph.D. Student Advised by Colin Raffel
Significant courses include:
TA for Graduate level Introduction to Machine Learning

Ph.D. Student Advised by Colin Raffel
Significant courses include:

Read and solved problems from various textbooks, including:
Audited lections and completed assignments for many online courses including:

Bachelor of Science, Double Major in Computer Science with Honors and Neuroscience
Significant courses include:

I finished high school at the Shanghai American School, Puxi campus in Shanghai China.